A Story of Basis and Kernel - Part II: Reproducing Kernel Hilbert Space
1. Opening Words
In the previous blog, the function basis was briefly discussed. We began with viewing a function as an infinite vector, and then defined the inner product of functions. Similar to Rn space, we can also find orthogonal function basis for a function space.
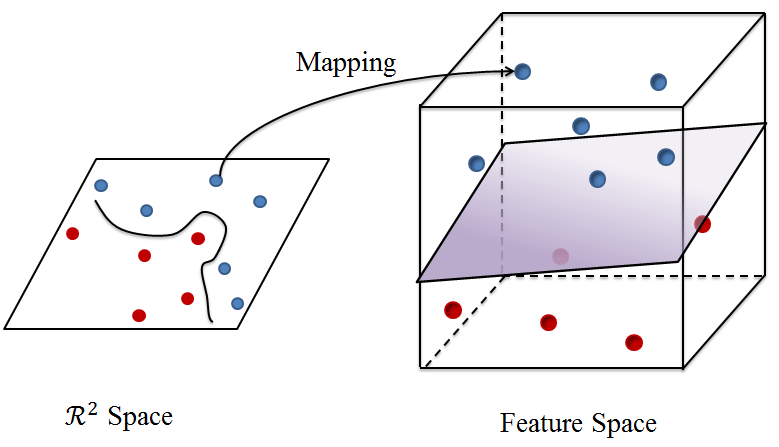
This blog will move a step further discussing about kernel functions and reproducing kernel Hilbert space (RKHS). Kernel methods have been widely used in a variety of data analysis techniques. The motivation of kernel method arises in mapping a vector in Rn space as another vector in a feature space. For example, imagine there are some red points and some blue points as the next figure shows, which are not easily separable in Rn space. However, if we map them into a high-dimension feature space, we may be able to seperate them easily. This article will not provide strict theoretical definition, but rather intuitive description on the basic ideas.
2. Eigen Decomposition
For a real symmetric matrix A , there exists real number λ and vector x so that
Ax=λx
Then λ is an eigenvalue of A and x is the corresponding eigenvector. If A has two different eigenvalues λ1 and λ2 , λ1̸=λ2 , with corresponding eigenvectors x1 and x2 respectively,
λ1x1Tx2=x1TATx2=x1TAx2=λ2x1Tx2
Since λ1̸=λ2 , we have x1Tx2=0 , i.e., x1 and x2 are orthogonal.
For A∈Rn×n , we can find n eigenvalues a long with n orthogonal eigenvectors. As a result, A can be decomposited as
A=QDQT
where Q is an orthogonal matrix (i.e., QQT=I ) and D=diag(λ1,λ2,⋯,λn) . If we write Q column by column
Here {qi}i=1n is a set of orthogonal basis of Rn .
3. Kernel Function
A function f(x) can be viewed as an infinite vector, then for a function with two independent variables K(x,y) , we can view it as an infinite matrix. Among them, if K(x,y)=K(y,x) and
∫∫f(x)K(x,y)f(y)dxdy≥0
for any function f , then K(x,y) is symmetric and positive definite, in which case K(x,y) is a kernel function.
Similar to matrix eigenvalue and eigenvector, there exists eigenvalue λ and eigenfunction ψ(x) so that
∫K(x,y)ψ(x)dx=λψ(y)
For different eigenvalues λ1 and λ2 with corresponding eigenfunctions ψ1(x) and ψ2(x) , it is easy to show that
Again, the eigenfunctions are orthogonal. Here ψ denotes the function (the infinite vector) itself.
For a kernel function, infinite eigenvalues {λi}i=1∞ along with infinite eigenfunctions {ψi}i=1∞ may be found. Similar to matrix case,
K(x,y)=i=0∑∞λiψi(x)ψi(y)
which is the Mercer's theorem. Here <ψi,ψj>=0 for i̸=j . Therefore, {ψi}i=1∞ construct a set of orthogonal basis for a function space.
Here are some commonly used kernels:
Polynomial kernel K(x,y)=(γxTy+C)d
Gaussian radial basis kernel K(x,y)=exp(−γ∥x−y∥2)
Sigmoid kernel K(x,y)=tanh(γxTy+C)
4. Reproducing Kernel Hilbert Space
Treat {λiψi}i=1∞ as a set of orthogonal basis and construct a Hilbert space H . Any function or vector in the space can be represented as the linear combination of the basis. Suppose
f=i=1∑∞fiλiψi
we can denote f as an infinite vector in H :
f=(f1,f2,...)HT
For another function g=(g1,g2,...)HT , we have
<f,g>H=i=1∑∞figi
For the kernel function K, here I use K(x,y) to denote the evaluation of K at point x,y which is a scalar, use K(⋅,⋅) to denote the function (the infinite matrix) itself, and use K(x,⋅) to denote the xth "row" of the matrix, i.e., we fix one parameter of the kernel function to be x then we can regard it as a function with one parameter or as an infinite vector. Then
K(x,⋅)=i=0∑∞λiψi(x)ψi
In space H , we can denote
K(x,⋅)=(λ1ψ1(x),λ2ψ2(x),⋯)HT
Therefore
<K(x,⋅),K(y,⋅)>H=i=0∑∞λiψi(x)ψi(y)=K(x,y)
This is the reproducing property, thus H is called reproducing kernel Hilbert space (RKHS).
Now it is time to return to the problem from the beginning of this article: how to map a point into a feature space? If we define a mapping
Φ(x)=K(x,⋅)=(λ1ψ1(x),λ2ψ2(x),⋯)T
then we can map the point x to H . Here Φ is not a function, since it points to a vector or a funtion in the feature space H . Then
<Φ(x),Φ(y)>H=<K(x,⋅),K(y,⋅)>H=K(x,y)
As a result, we do not need to actually know what is the mapping, where is the feature space, or what is the basis of the feature space. For a symmetric positive-definite function K , there must exist at least one mapping Φ and one feature space H so that
Support vector machine (SVM) is one of the most widely known application of RKHS. Suppose we have data pairs (xi,yi)i=1n where yi is either 1 or -1 denoting the class of the point xi. SVM assumes a hyperplane to best seperate the two classes.
β,β0min21∥β∥2+Ci=1∑nξi
subject to ξi≥0,yi(xiTβ+β0)≥1−ξi,∀i
Sometimes the two classes cannot be easily seperated in Rn space, thus we can map xi into a high-dimension feature space where the two classes may be easily seperated. The original problem can be reformulated as
That is, β can be writen as the linear combination of xis! We can substitute β and get the new optimization problem. The objective function changes to:
What we need to do is determining a kernel function and solve for α,β0,ξi . We do not need to actually construct the feature space. For a new data x with unknown class, we can predict its class by
Kernel methods greatly strengthen the discriminative power of SVM.
7. Summary and Reference
Kernel method has been widely utilized in data analytics. Here, the fundamental property of RKHS is introduced. With kernel trick, we can easily map the data to a feature space and do analysis. Here is a video with nice demonstration on why we can easily do classification with kernel SVM in a high-dimension feature space.
The example in Section 5 is from
Gretton A. (2015): Introduction to RKHS, and some simple kernel algorithms, Advanced Topics in Machine Learning, Lecture conducted from University College London.
Other reference includes
Paulsen, V. I. (2009). An introduction to the theory of reproducing kernel Hilbert spaces. Lecture Notes.
Daumé III, H. (2004). From zero to reproducing kernel hilbert spaces in twelve pages or less.
Friedman, J., Hastie, T., and Tibshirani, R. (2001). The elements of statistical learning. Springer, Berlin: Springer series in statistics.)