A Summary of State-space Models
1. Bayesian Filter
In this article, I summarize some famous state-space models. Here I won't go into details but focus on the entire map to get an overview. All these state-space models originate from Bayesian filter. In these models, two stochastic processes are considered. The first process is states , and the second process is observations or measurements , where means "time" but generally the processes are not restricted to time series. We are interested in the true value of states, but we can only observe the value of observations. Therefore, state-space models aim to estimate states based on observations. Two relationships should be addressed:
- The state-to-state probability
- The state-to-observation probability No direct relationship exists between any two observations. A common assumption is the Markov property, which assumes that the current state depends only on the previous state, namely .
2. Prediction and Updating
State-space model has online algorithms with recursive two steps. Prediction is to estimate the posterior distribution based on the distribution , according to the state-to-state probability . Mathematically,
Updating is to update the previous distribution based on the latest observation . Mathematically,
3. Considerations in Modeling
Bayesian filters estimate by the posterior distribution . Usually the state-to-state probability and state-to-observation probability cannot be obtained directly when modeling practical problems. Instead, they should be inferred from prediction model and measurement model . And a series of questions must be answered:
- Is state discrete or continuous?
- What is the distribution of ?
- Is the prediction model linear or nonlinear?
- Is the measurement model linear or nonlinear? According to different answers to these questions, we have different filters as follows.
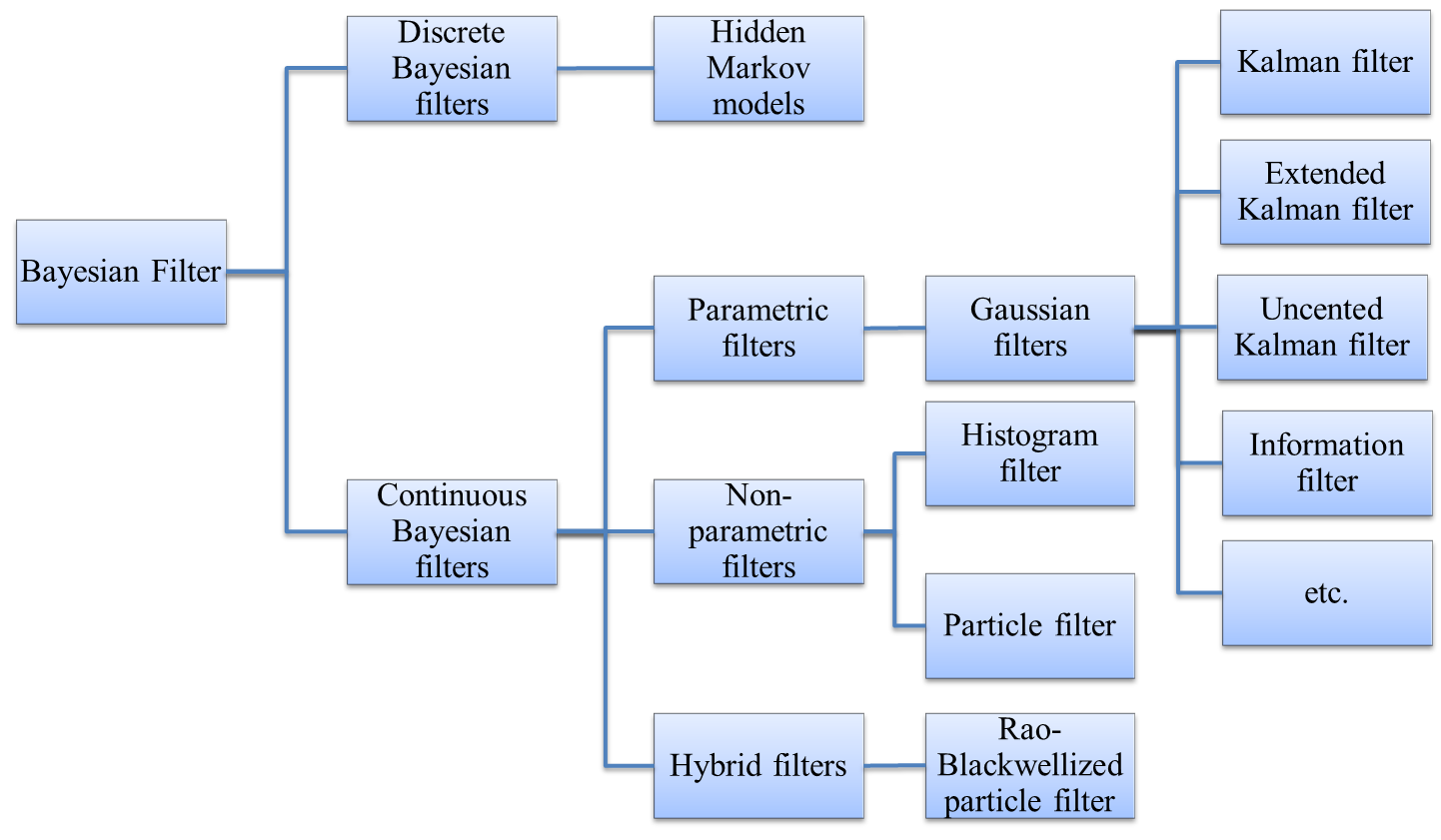
4. Classification of Bayesian filters
Based on whether the state is discrete or continuous, Bayesian filters are divided into discrete filters and continuous filters. When state can only be discrete values, the state-to-state probability can be expressed by transition matrix where .
Based on whether the distribution of is assumed to be a specific format, continuous Bayesian filters are divided into parametric and nonparametric filters. For example , in Gaussian filters, the distribution of is assumed to be multivariate normal distribution. With this assumption, the posterior distribution can be expressed in close-form explicitly. On the other side, non-parametric filters don't make any assumptions in the distribution of , but use some techniques to approximate the distribution. For example, the distribution of can be expressed by a histogram (Histogram filter) or a lot of samples (Particle filter) drawn from the target distribution. Non-parametric filters approximate the distribution, and put no restrictions on prediction model and measurement model , thus flexible in various situations. However, the computation load is heavy since there is no close-form expression, and the better of the approximation, the heavier of the computation burden.
Gaussian filters assume the distribution of to be multivariate normal distribution. In classical Kalman filter, the prediction model and the measurement model are assumed linear in order to maintain normality. Specifically, . Derivatives of Kalman filter such as Extended Kalman filter and Uncented Kalman filter relax the linear relationship assumption, but approximate by linearization techniques such as Taylor expansion. Information filter and its derivatives are essentially the same to Kalman filter family, with information expression of multivariate normal distribution .
Hybrid filters are mixture of parametric and non-parametric filters, with some dimensions of state assumed to be in specific format and other dimensions to be expressed in non-parametric techniques.